Wan 2.2 相比上一版本的优势
Wan 2.2 是由阿里巴巴旗下 Wan AI 研究团队开发的新一代 AI 视频生成模型。该模型专为文本到视频和图像到视频任务设计,能够快速生成高质量、具有电影级质感的视频,并具备更自然的动态效果。相比 Wan 2.1,Wan 2.2 采用了强大的 Mixture of Experts(MoE)架构,带来更流畅的生成过程、更精准的提示词对齐以及更强的视觉控制能力。
Select the model you want to generate your video with.
开源与电影级精度的结合,借助 Wan 2.2 的强大能力。
Wan 2.2 是由阿里巴巴旗下 Wan AI 研究团队开发的新一代 AI 视频生成模型。该模型专为文本到视频和图像到视频任务设计,能够快速生成高质量、具有电影级质感的视频,并具备更自然的动态效果。相比 Wan 2.1,Wan 2.2 采用了强大的 Mixture of Experts(MoE)架构,带来更流畅的生成过程、更精准的提示词对齐以及更强的视觉控制能力。
阿里巴巴 Wan 2.2 完全开源,采用 Apache 2.0 许可证。开发者可以自由下载、使用和修改 Wan 2.2 AI 视频生成工具,用于科研或商业用途。这种开放方式赋予创作者和工程师极大的灵活性,可用于构建定制化的视频处理流程,并将其集成到自己的工具中。
该模型可将文本提示转换为 5 秒钟的 480P 或 720P 视频。依托强大的提示理解和动作控制能力,其生成结果比之前的 Wan 视频模型或竞品 AI 工具更精准、更具表现力。
专为将静态图像转化为动态片段而设计,支持 480P 和 720P 输出。该模型可减少镜头抖动,支持多种风格,适用于艺术创作和分镜脚本等场景。
TI2V-5B 模型支持文本到视频与图像到视频的统一生成流程。采用高效压缩的 VAE 模型实现快速的 720P@24fps 视频生成,可在单块消费级 GPU(如 RTX 4090)上高效运行,适合研究或生产使用。
Wan 2.2 集成了强大的专家混合(Mixture-of-Experts)架构,在不增加计算成本的前提下显著提升模型容量。这使得视频生成在时间步长上更快速、更高质量,确立了 Wan 2.2 在开源扩散模型领域的技术领先水平。
Wan 2.2 的训练数据相较前代 Wan 2.1 增加了 65.6% 的图像和 83.2% 的视频。这一大幅提升使生成视频在动作表现、语义连贯性和视觉风格一致性方面更加出色。
基于高质量标注的光照、构图与调色数据集,Wan 2.2 在生成视觉震撼的电影风格视频方面表现出色,为创作者提供对艺术风格的精准控制。
Wan 2.2 TI2V-5B 模型支持以 720P 分辨率、24fps 生成视频,采用先进的 VAE 压缩技术(16×16×4)。该模型专为高效运行设计,可在如 NVIDIA RTX 4090 等消费级显卡上运行,让高质量视频生成更易于使用。
您可以在 Hugging Face Space 上直接体验 Wan 2.2 AI 视频生成器。该 TI2V-5B 模型支持文本到视频和图像到视频生成,分辨率为 720p,帧率为 24fps。
访问 Wan AI 官方网站,体验 Wan 2.2 Plus,这是一个功能更强大的版本,提供增强工具和预设工作流。适合希望获得更多控制权和更快生成速度的用户。请注意,Wan 2.2 Plus 目前是付费服务。
首先克隆官方 Wan 2.2 GitHub 仓库。这里包含了在本地运行模型所需的所有资源。

请确认您的环境符合要求。安装仓库中列出的 Python 包,并确保 PyTorch 版本为 2.4.0 或更高,以兼容 Wan 2.2。

根据使用场景选择合适的模型: T2V-A14B 用于文本到视频的生成 I2V-A14B 用于图像到视频的生成 TI2V-5B 支持文本+图像混合输入,支持 720p 分辨率、24fps 输出格式 您可以在 Hugging Face 和 ModelScope 上下载并了解更多关于每个模型的信息。
完成设置后,您可以使用文本提示或图像开始生成视频。模型将处理您的输入并生成高质量的 720p 输出,所有操作均在本地机器上完成,您可以完全掌控视觉风格、动作和时间节奏。
您可以在 ComfyUI 内直接使用 Wan 2.2 TI2V-5B 视觉化工作流生成视频。该设置支持文本到视频和图像到视频的生成。要开始使用,请参考 Wan 2.2 ComfyUI 指南,其中详细说明了模型加载与工作流运行的步骤。
在 ComfyUI 中运行 Wan 2.2 需要手动安装特定的模型文件:扩散模型、VAE 和文本编码器。建议使用至少 8GB 显存的 GPU,以保证流畅生成。
ComfyUI 目前支持三种 Wan 2.2 工作流: T2V(文本转视频) I2V(图像转视频) TI2V(混合输入) 每种模式均可根据您的提示文本、分辨率和帧率偏好进行调整,适用于创作者、研究人员和开发者。
Wan 2.2 采用专家混合(MoE)设计,在高质量生成与计算效率之间取得平衡。在去噪过程中,它会动态切换两个专家模型——一个专攻高噪声阶段,另一个负责低噪声优化。这种分层结构使 Wan 2.2 能在不增加内存占用的情况下,生成更精细稳定的视频结果,表现更优相比 Wan 2.1。

针对希望在消费级硬件上获得更快性能的用户,Wan 2.2 提供了 TI2V-5B 模型。该模型通过高效 VAE 压缩视频表示,在单个 GPU 上即可实现 720p 24fps 视频生成,耗时低于 9 分钟。该模型支持文本到视频和图像到视频任务,统一处理流程,操作便捷。
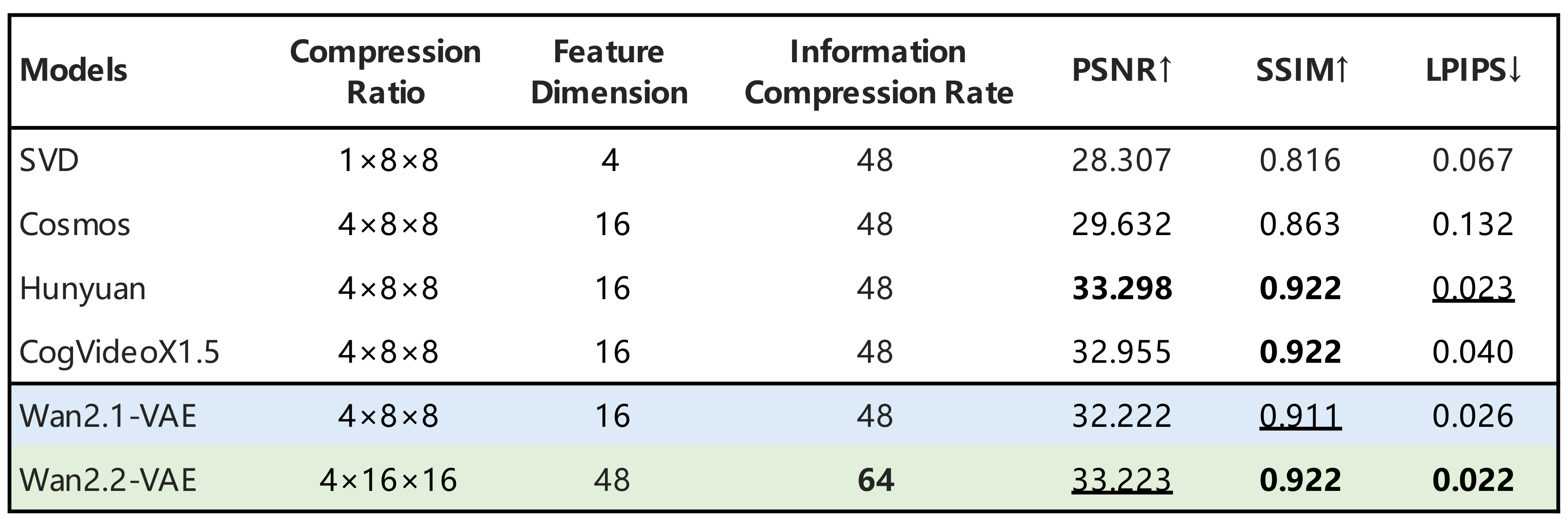
在基准测试中,Wan 2.2 在运动、结构和提示对齐方面表现出显著提升。它在关键评估指标上始终领先于主流商业视频模型,提供更真实、连贯的输出体验。
现在您可以免费在线试用我们的 AI 视频生成器 Vidful.ai,无需注册。我们即将全面集成 Wan 2.2 AI 视频生成器,让您轻松使用先进的 Wan AI 模型,快速高效地生成高质量、电影感的视频。
Wan 2.2 是一个开源的视频生成模型,具备增强功能,比如 Mixture-of-Experts 架构和电影级美学设计。
是的,Wan 2.2 完全开源,包含 TI2V-5B 模型及其用于文本到视频和图像到视频生成的配套组件。
Wan 2.2 经过优化,可在 NVIDIA RTX 4090 等消费级显卡上运行,支持高质量的 720P@24fps 视频生成。
T2V 是根据文本提示生成视频,I2V 是从静态图像生成视频,TI2V 支持混合输入以提升灵活性。
可以。这个开源许可证支持学术和商业使用,具体权限请查看许可证文件。
Wan 2.2 在 Wan-Bench 2.0 等关键基准测试中表现优于主流商业模型,输出质量达到行业标准,并且完全透明。
目前支持 480P 和 720P 分辨率的视频生成,未来会支持更高分辨率。